The internet is an incredible market place hosting millions and millions of software products to make our lives indefinitely easier. To keep up with each other, software grew more and more elaborate to provide us customers with lots of different features and services to finally make us purchase a thing or two. Now due to the resulting increase of complexity we must take special care not to break existing features while developing the next big version brimming full of features. Testing that the next code increment does not break existing stuff is what we testers call „regression testing“, and there is one especially economical way of doing that: test automation.
That’s what we’re going to do today. We gonna test and we gonna automate and we do all that in Java this time. Because everyone knows about Java, right? So let’s write once and run everywhere. Given we have a browser there.
To start our test automation journey – again -, we will work with the following tools. The versions are the ones I used at the time of writing. I might update them in the future.
After downloading and installing these tools from their respective web sites, we’re ready to start our system under test.
Deploying the system under test
To achieve this, we simply run the following command:
docker run --name spree --rm -d -p 3000:3000 spreecommerce/spree:3.6.4
If it went well, a quick glance at http://localhost:3000/ should show a catalog page full of cute Rails merch. Now we will install and prepare Selenium.
Geckodriver installation and management
Contrary to the Python version, we use WebDriverManager to free us from the installation hassle of Geckodriver, hence we are done with this step. The tip was sent to me by my good friend Sho. Thank you, mate. I owe you one! 🙂
Initializing our test automation project
Given a successful Gradle installation as linked in the shopping list we can now create our test project. Please open a terminal in a root directory of your choice and do:
mkdir jata_tutorial && cd jata_tutorial
gradle init
When prompted answer with 1 for a basic project and then 2 for Kotlin as our Gradle DSL.
Of course we will use the new APIs as well, since we love to live on the edge here. Please choose „yes“ here.
Finally, when asked, give your project the default name that is the project root directory’s name. Now your boilerplate project is set up and ready to go.
Now it’s time to define our dependencies. In build.gradle.kts please introduce the following lines:
plugins {
java
}
group = "your.groupid"
version = "1.0-SNAPSHOT"
repositories {
mavenCentral()
}
dependencies {
implementation("org.slf4j:slf4j-api")
implementation("ch.qos.logback:logback-classic:1.4.5")
implementation("org.apache.commons:commons-lang3:3.12.0")
testImplementation("org.seleniumhq.selenium:selenium-java:4.7.2")
testImplementation("io.github.bonigarcia:webdrivermanager:5.3.1")
testImplementation(platform("org.junit:junit-bom:5.9.1"))
testImplementation("org.junit.jupiter:junit-jupiter:5.9.1")
}
tasks.getByName<Test>("test") {
useJUnitPlatform()
}
This sets up our project with some basic metadata like our groupId and a (somewhat) meaningful version. We defined to use Java as our JVM language and JUnit as our test runner. Additionally we will have access to Maven’s central repository, where Gradle can download our project dependencies that we defined in the section of that exact same name.
With these dependencies, we are able to:
- automagically download and install webdriver executables for Selenium (in our case: Geckodriver)
- perform Selenium actions including opening and closing browser windows, enter URLs and clicking stuffs
- generate random test input strings
- log things to the console in a nice timestamped format (without being scared of Log4Shell)
- and do all that in a modern
JUnit5 – runner
Everything that we need to do very soon.
The boilerplate
Next up, we create the skeleton of our first test class. In src/test/java, please create a file named CrossTests.java containing the following code. Please note that .java source files should be named after the contained class. Here: CrossTests.
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.openqa.selenium.WebDriver;
class CrossTests {
WebDriver driver;
@BeforeAll
static void setupClass() {
}
@BeforeEach
void setup() {
}
@AfterEach
void teardown() {
}
@Test
void isOpen() {
}
}
Great. That looks almost like a real test already. Finally we are going to open a browser window.
Starting and closing the browser
In setupClass we call the WebDriverManager and let it work its Geckodriver-initializing magic.
@BeforeAll
static void setupClass() {
WebDriverManager.firefoxdriver().setup();
}
Then we ensure that a browser is opened before each of the individual tests marked with @Test:
@BeforeEach
void setup() {
this.driver = new FirefoxDriver();
this.driver.manage().timeouts().implicitlyWait(Duration.of(5, ChronoUnit.SECONDS));
}
This opens a Firefox window whenever we execute one of the class‘ test methods. This is a very pure and uncustomised instance; we could configure it further if we wanted. But for our purpose at the moment, it is perfectly fine.
Now before we perform any actions on the page, we must make sure that the browser window is closed appropriately after each test run. In teardown, we do:
@AfterEach
void teardown() {
this.driver.quit();
}
Caveat: confusion potential
Selenium’s WebDriver class has a close()-method, but please always use quit() instead. It performs a clean browser termination with regards to Selenium’s execution flow, whereas close() will just terminate the browser causing you lots of warnings in the log.
Alright! We have taken care of the browser handling. Time to do stuffs with it.
Opening the landing page
The most basic action ist to open a web page. Thankfully this task is handled by Selenium with a simple one-liner. Given that our sample web shop is up and running, we do:
this.driver.get("http://localhost:3000/");
We introduce the line to the test case method isOpen, which we introduced earlier in our boiler plate. But before we head into executing the test case, we have to be aware of the fact: We as the user can see the page being open, but the computer cannot. We have to programmatically verify that our expectation „landing page is open“ is met.
Verifying the outcome
To do that we verify these 3 conditions:
- the window title contains the landing page’s HTML
title
- the most prominent logo exists on the web page and
- it’s actually visible (i.e. it does not have its
display property set to none).
We add this code directly below the line that opens the website:
assertTrue(this.driver.getTitle().contains("Spree Demo"),
"'Spree Demo' is not in the browser's title.");
WebElement logoElement = this.driver.findElement(By.id("logo"));
assertTrue(logoElement.isDisplayed());
The first line peeks into the page title, which is another staple of Selenium, and then checks if it contains „Spree Demo“. Using JUnit’s assertTrue, we verify that this is the case, and if not, we print a custom error message. Condition 1 done.
The second line depicts the method you will probably use the most whilst moving forward in your test automation career: Webdriver#findElement goes through the page’s DOM and grabs the element that meets the given criteria. Here we search for an element with the HTML id „logo“. If it fails to find the element, it drops a NoSuchElementError. Therefore, we just implicitly verified condition 2.
The return value is a WebElement object that we can do clicks, inputs and various other actions on. We will use the object’s method isDisplayed() to check if the logo is visible therefore verifying our 3rd condition.
Straight-forward so far. At this point your code should look like that:
import io.github.bonigarcia.wdm.WebDriverManager;
import org.junit.jupiter.api.*;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.time.Duration;
import java.time.temporal.ChronoUnit;
import static org.junit.jupiter.api.Assertions.*;
class CrossTests {
WebDriver driver;
@BeforeAll
static void setupClass() {
WebDriverManager.firefoxdriver().setup();
}
@BeforeEach
void setup() {
this.driver = new FirefoxDriver();
this.driver.manage().timeouts().implicitlyWait(Duration.of(5, ChronoUnit.SECONDS));
}
@AfterEach
void teardown() {
this.driver.quit();
}
@Test
void isOpen() {
this.driver.get("http://localhost:3000/");
assertTrue(this.driver.getTitle().contains("Spree Demo"),
"'Spree Demo' is not in the browser's title.");
WebElement logoElement = this.driver.findElement(By.id("logo"));
assertTrue(logoElement.isDisplayed());
}
}
Let’s execute it. In a terminal window, please switch to the project root and do:
./gradlew test
If everything went well, your console should display a big OK:
BUILD SUCCESSFUL in 7s
4 actionable tasks: 2 executed, 2 up-to-date
Congratulations, you just executed your first Java-Selenium-test:
Our shop’s landing page can be opened and it is displayed correctly.
What is this driver thingy by the way?
Simply put, the driver – in our case Geckodriver – is the glue between our code and Firefox. The same would be valid for Chrome with Chromedriver respectively. This means it is the interface to our browser handling all the requests that we perform :
findElementclick- „are you displayed?“
- perform key strokes
- „grab that text of an element“
- etc. pp.
Under the hood, drivers are http server applications that receive requests sent by Selenium everytime we perform an action similar to these mentioned above. The driver then interacts with the browser in the way we tasked it to and sends a JSON-based response that we can base our future work on. Everything is encapsulated by Selenium so that we can work with simple objects during automating our tests without having to deal with HTTP or JSON.
Performing and validating browser actions
Now that we know the basics of how to write automated tests with Java and Selenium, let’s develop a more complex test.
The best candidates for automation are cross tests. These are tests that cover representative cross sections of the product. One example could be: Put items into the cart, view the cart page and perform the checkout. It is a great practise to start test automation for new projects by coding these cross tests first.
For the sake of brevity here, we will write up the test until reaching the checkout page. The rest is homework. Don’t worry, I got you covered with the full source code in my bitbucket repo.
Ok, without further ado, here’s the code. Please add the following method to the test class.
@Test
void findSpreeBagAndCheckout()throws InterruptedException{
this.driver.get("http://localhost:3000/");
// Landing and catalog page
this.driver.findElement(By.cssSelector("[href='/t/spree']")).click();
this.driver.findElement(By.cssSelector("a[href*='spree-bag']")).click();
// Product page
this.driver.findElement(By.cssSelector("input#quantity")).clear();
this.driver.findElement(By.cssSelector("input#quantity")).sendKeys("3");
this.driver.findElement(By.id("add-to-cart-button")).click();
// Cart page
assertTrue(this.driver.getTitle().contains("Shopping Cart"),"'Shopping Cart' is not in the browser's title.");
this.driver.findElement(By.cssSelector("img[src$='/spree_bag.jpeg']")).isDisplayed();
String qtyValue=this.driver.findElement(By.cssSelector(".line_item_quantity")).getAttribute("value");
assertEquals(qtyValue,"3","The item quantity is not the same we typed in!");
String cartTotal=this.driver.findElement(By.cssSelector(".cart-total > .lead")).getText();
assertEquals(cartTotal,"$68.97","The total cart value does not match our expectations. That's a blocker!");
}
What’s new here?
If we look back at our first landing page test, you will notice that we use a lot of new things. We will cover them one by one in the next section.
CSS selectors
One thing that catches the eye is that we looked for elements by using CSS expressions. You may have heard about them from your frontend peers, or maybe you have even worked with them yourself already. If not, don’t worry. We will cover them in a followup post. For now, I will give you a few translations:
[href='/t/spree']
„Give me a page element, whose attribute href is equal to ‚/t/spree'“. Quick reminder: href is used in link elements for defining the target URL that is opened, when the user clicks the link.
a[href*='spree-bag']
„Give me any link („anchor“) element, whose attribute href contains ’spree-bag‘.“
img[src$='/spree_bag.jpeg']
„Give me an image element, whose attribute src ends with ‚/spree_bag.jpg‘.“
input#quantity
„Give me an input element, whose HTML id is equal to ‚quantity‘.“ Yes, we could have used By.ID with „quantity“ here, but in this case I wanted to be explicit about the element type input.
.line_item_quantity
„Give me an element that has line_item_quantity in its class attribute.“ The leading dot indicates that we are looking for elements that has the specified class in its class list. It is roughly equivalent to [class*='line_item_quantity'].
.cart-total > .lead
„Give me any element that has the lead class and that’s preceded by any element that has the cart-total class.“
By using CSS selectors you can be very specific about what element you want to use in your test case. This makes CSS selectors incredibly powerful and versatile while maintaining a solid degree of simplicity, especially compared to XPath (ugh).
New properties and methods used in our test case
Aside from CSS selectors, we used several new methods and properties in our automated test.
click() issues a click on the target element. Straight-forward.
.getText() returns the element’s written text. In <p>Some text</p> for example, we would get access to „Some text“.
getAttribute("someHtmlAttribute") gives us the content of an element’s HTML attribute. In our test we fetch an element’s value attribute that is often used to set the content of an input element. Another example might be the link element we talked about earlier. Given we want to have its href attribute for some further verifications; on our page:
<a id="mylink" href="https://www.example.org">an example link</a>
Then in our test we could do:
targetHref = this.driver.findElement(By.id("mylink"))
.getAttribute("href");
this.doSomeStuffsOn(targetHref);
.sendKeys("My desired input") imitates key strokes on an element. We use it to type any string we want into our target text input element. In our test for example that would be the „quantity“ input box.
And finally, with clear() we have a little helper in our toolbox that removes any content from an input element. In our test we use that to remove the preset value. Otherwise we would accidentally order 31 bags: „3“ from us and „1“ from the value preset by the page.
Continuing your test automation journey from here
Alright, let’s sum up what we accomplished:
We have seen how to open and close a browser window, do various actions on the page and verify their outcomes. Finally, we used that to write a fairly large cross test, all of that on a full fledged ecommerce web app. Great job! Now where should we go next? For the next post, as promised, I’d like to go back one step and give you a deeper introduction to CSS expressions, because they will accompany you for a long time during your test automation journey. Afterwards we have a big problem to solve that you probably already noticed:
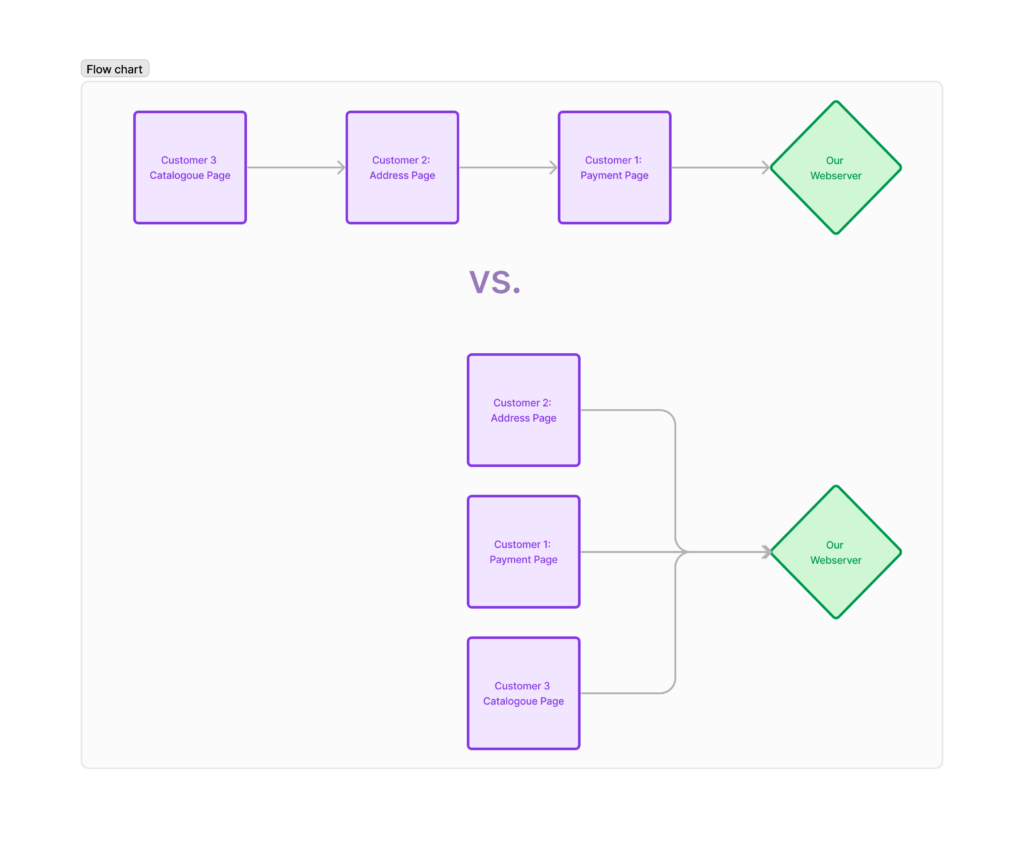
Copious amounts of repetition.
To tackle that we will leverage cucumber-jvm, a Behavior Driven Development framework that makes it possible to write test cases in human-readable text form on top of a DRY Java code base. Afterwards we will apply the Page Object Pattern, a test automation – specific design pattern that reduces repetition even more.
Okay! To keep you busy while I am busy, how about finishing the checkout? As a reminder, you can find the full source code in my bitbucket repo at any time. Alternatively you can spoil yourself a little about Cucumber in Rust or try Python instead of Java.
Stay curious and see you in the next post!